How I Designed a Custom Protocol for My App
Roj
Introduction
Rast (in Kurdish: “ڕاست” [raːst]) is a new experimental project of mine for detecting orthographical errors in texts written in the Central Kurdish language, also known as Sorani.
I designed it in a way that works very efficiently with long texts over a duplex network connection. To do this, I first created K8, an 8-bit coding standard for Kurdish.
K8
This was designed because Kurdish characters are non-ASCII, and take two bytes each when encoded using UTF-8, making them very unefficient for binary protocols.
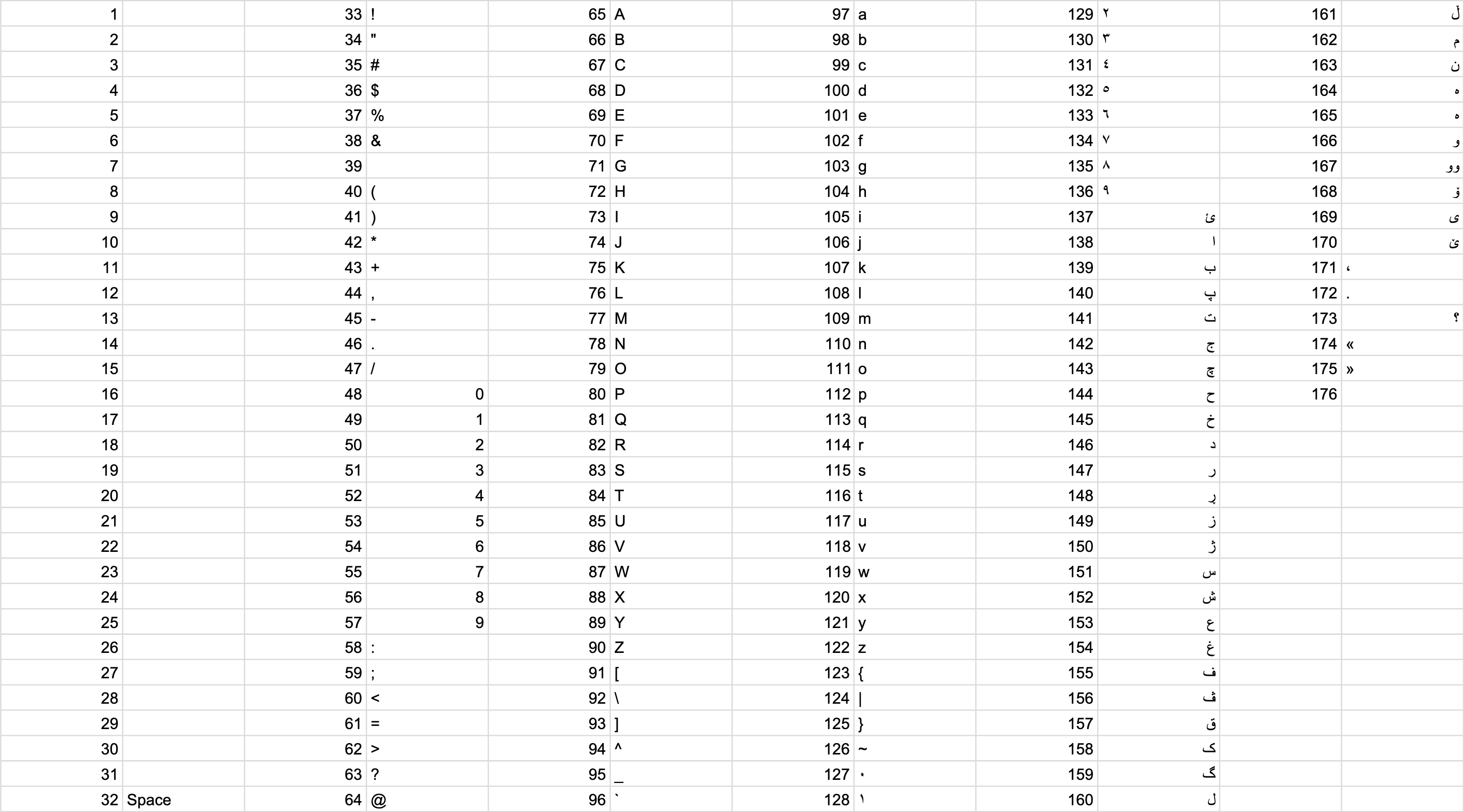
It also supports backward-compatibility for non-covered UTF-8 characters when needed by encoding an optional footer.
Below is an example of that.
00 -- version
97 -- س
A1 -- ڵ
8A -- ا
A6 -- و
AB -- ،
20 -- space
00
00
00
21 -- !
01 -- footer start
D0
BC -- м
D0
B8 -- и
D1
80 -- рThe above is a representation of the literal سڵاو، мир!.
This footer-based compatibility is used K8 is used in Rast's URL state, and the version without it is used in the transport protocol as described below.
The Transport Protocol
The goal of the project is straightforward: receive a stream of text, stream back a list of errors.
Errors are made up of their details, which are two strings of text: a generic title and a specific description.
Each component of an error’s detail is transported once only. Afterwards, their references will be kept by both the server and the client throughout the WebSocket connection.
Below is a brief representation of it.
+-------------------------------------------------------------------+ header
| uin16 - error count | header
+-------------------------------------------------------------------+ header
| uin16 - detail count | header
+-----------------------+-------------------------------------------+ errors
| uint16 - error offset | uint8 error length | errors
+-----------------------+-------------------------------------------+ errors
| ..................... | .................. | errors
+-----------------------+-------------------------------------------+ details
| uint8 title length | uint8 desc length | uint16 errorCount | details
+-----------------------+-------------------------------------------+ details
| ..................... | .................. | details
+-----------------------+-------------------------------------------+ details
| title | description | uint16[] error_indexes | details
+-----------------------+-------------------------------------------+ details
| ..................... | .................. | details
+-----------------------+-------------------------------------------+ detailsHere are some details that might have been missed above:
The first two bytes of each packet
error_countcounts the number of errors found inside a text input.The upcoming two bytes
detail_countis the number of error details returned on this round.The next group of bytes with a length of
3 * error_countmarks the positions of the errors inside the text.What comes next are
detail_countheaders of the error details.The last group is the error details and the indexes of the errors they apply to.
The fields
titleand thedescriptionwill either be an arbitrary cache index, or the human-readable information about the errors encoded in K8, depending on whether they were previously sent throughout the connection.
Conclusion
This protocol took a while to design, and I like how it turned out. I considered using bit-based streaming, but I failed to get it into production due to the development cost. I will be writing about updates on it below if there were any in the future.